Search Overview
In order to offer desktop search functionalities, TagSpaces provides a variety of search-related features, which are described in this section.
With the search functionality, you are able to find files and folders by their name, tags, and other properties. The search algorithm considers different weights for the following properties of the indexed entries, with the file or folder name being the strongest signal:
- The name of the file or the folder
- The description added to the file or the folder
- The path of the file, including the names of the parent directories. For example, if you are searching for photos from your vacation in the USA and the folder where these files are located contains the word USA (e.g.,
20160301 vacation usa), the search will list all the files located directly in this folder. - The tags (and their descriptions) assigned to the file or the folder
- The content of supported plain-text files (
.txt,.md,.html, source code, etc.) if full-text search is activated for the current location. Plain-text full-text search is a free feature since version 6.12. - PRO The content of supported office and document formats (PDF, DOCX, ODT, XLSX, PPTX, EPUB, …) when full-text search is activated on the location.
Open the search
The user can start a search by switching to the search area by pressing the Ctrl+F / Cmd+F key combination. It can also be opened by clicking on the search text field.
Once activated, you can start entering the tags or other search terms. If you choose to enter tags with the + symbol, you will see suggestions (1) and you can choose from them with the arrow UP and DOWN keys. The search can be started by hitting the ENTER key or by clicking on the search button (4). You can close the search mode with the ESC key or by clicking on the X-button (3).
The advanced search options, visible in the next screenshot, can be accessed after clicking on the button with the sliders (2) from the previous screenshot.
Search query
The search query consists of two parts. The first one is just a simple free text that is searched in the index. The second component is a list of tags. Here, you can define a more precise query by including and excluding tags. You can use the following shortcuts to add, remove, or exclude certain tags:
+- Will add the tag to the Must contain all of the tags field — logical AND|- Will add the tag to the At least one tag field — logical OR-- Will add the tag to the None of these tags field — logical NOT
The tags specified here will be visible in the search options described in the previous paragraph.
Example search queries:
+usa +beach -sunset jpg— files and folders withjpgin the name or content, tagged withusaandbeach, but notsunset.|beach |sunset— files and folders tagged withbeachorsunset(at least one).project discussion— files where bothprojectanddiscussionappear (the default is fuzzy matching — see Search accuracy for strict variants)."quarterly report"— files containing the exact phrase. Double quotes keep the words together.
Pasting a complex query
You can compose the entire query externally and paste it into the search box in one go, for example:
project notes +work +urgent -draft |client-a
When the pasted (or fully typed) input contains a text term together with any tag prefix (+, -, or |), TagSpaces recognizes every token, creates the corresponding tag chips, and routes the remaining words into the free-text part. Pressing ENTER immediately runs the search.
Search query composition
The opened dropdown has two sections. The first is Actions, described below, and the second is Search query composition, which lets you compose complex queries by combining tags with filters for file type, size, dates, scope, and accuracy.
The following commands are currently supported:
- AND tag — Typing
+shows the tag suggestions; select to require the tag on every result. - OR tag — Typing
|shows the tag suggestions; select to allow results tagged with at least one of them. - NOT tag — Typing
-shows the tag suggestions; select to exclude results with that tag. - File type — Typing
t:presents supported file type groups to narrow results (documents, images, notes, etc.). - File size — Typing
si:presents predefined size buckets. - Last modified — Typing
lm:presents predefined time windows. - Date created — Typing
cd:presents predefined creation-date windows. - Search scope — Typing
sc:lets you pick between current folder, current location, or global search. - Search accuracy — Typing
a:toggles between fuzzy, semistrict, or strict matching.
The chip row reorders itself for clarity: scope and accuracy chips come first (they are search-wide modifiers), filter chips (type, size, dates) in the middle, and tag chips last.
App actions
In the search menu, you can also start some common actions just by using your keyboard. The following commands are currently supported:
- Locations - Typing
l:will list the current locations, allowing you to easily find and open one by typing the first few letters. - Filter - Typing
f:will filter the current content of the folder without starting a new search. - History - Typing
h:will list the last opened or edited files so you can filter and open one of them. - Bookmarks - Typing
b:will allow you to filter and open your bookmarked files or folders. - Saved search query - Typing
q:will allow you to filter and start your saved search queries. - Search history - Typing
s:will allow you to find and execute search queries you have used in the past.
Search scope
The search algorithm can be required to deliver results for the following search scopes:
- Location — will deliver results from the current location. This is the default scope.
- Folder — will deliver results for the current folder, including all sub-folders.
- Global — will search in all configured locations. You can find more in the Global Search section.
Search accuracy
Three search accuracy modes are supported. In every mode, a query with multiple words behaves as a logical AND — every term must match somewhere in the entry. Quote a phrase with "..." to keep words together as a single term.
-
Fuzzy (default) — tolerant matching that forgives typos and incomplete words. Fuzzy mode also enables an advanced query syntax (powered by Fuse.js extended search) that lets you fine-tune the results.
White space acts as an AND operator, while a single pipe (
|) character acts as an OR operator. To escape white space, use double quotes — e.g.="vacation photos"for an exact-match phrase.Token Match type Description reportfuzzy-match Items that fuzzy match report=invoiceexact-match Items that are exactly invoice'budgetinclude-match Items that include budget!draftinverse-exact-match Items that do not include draft^meetingprefix-exact-match Items that start with meeting!^archiveinverse-prefix-exact-match Items that do not start with archive.pdf$suffix-exact-match Items that end with .pdf!.tmp$inverse-suffix-exact-match Items that do not end with .tmp -
Strict — case-sensitive, no fuzziness. Each term must appear verbatim in one of the searched fields.
-
Semistrict — like strict but case-insensitive.
Reportalso matchesreportorREPORT.
Starting with version 6.11, strict and semistrict queries also support multi-word AND semantics and "quoted phrases", matching how fuzzy mode already worked.
The default fuzzy matching is tuned to forgive typos but reject unrelated short-string collisions. If a search feels too strict for your data, switch to a: fuzzy (the default) — strict and semistrict are only meant for exact-lookup workflows.
Search for tagged entries
To support detailed search for tags, the user interface for entering them is split into three input fields:
- Must contain all of the tags - all tags listed here must be attached to the files or folders for them to appear in the search results (logical AND).
- At least one tag - any file or folder containing one of the tags listed here will be included (logical OR).
- None of these tags - entries with any of the tags listed here will be excluded from the search results (logical exclusion).
Search filters
Filter by file type
In the file type dropdown, you can specify which types of files to search. The file types are grouped into the following sections:
- Pictures and Photos: e.g., JPG, PNG, GIF
- Documents: e.g., PDF, ODF, DOCX, XLSX
- Notes: e.g., MD, TXT, HTML
- Audio files: e.g., OGG, MP3, WAV
- Video files: e.g., WEBM, OGV, MP4
- Archives: e.g., ZIP, RAR, TGZ, 7Z
- Bookmarks: e.g., URL, LNK
- eBook: e.g., EPUB, MOBI, AZW, PRC
- Emails: e.g., EML, MSG
In addition, there are special filters:
- Folders - limits the search to only folders.
- Files - limits the search to only files.
- Untagged files and folders - displays only files and folders that are not tagged.
Filter by file size
In this dropdown, you can filter files by their size. The following options are supported:
- Empty - filters files with zero size.
- Tiny - filters files smaller than 10KB.
- Very small - filters files smaller than 100KB.
- Small - filters files smaller than 1MB.
- Medium - filters files smaller than 50MB.
- Large - filters files smaller than 1GB.
- Huge - filters files larger than 1GB.

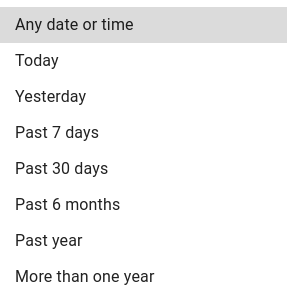
Filter by creation and last modified date
Here you can specify the time period in which the files you're searching for should have been modified. This filters supports the following options:
- Today - shows files and folders modified today.
- Yesterday - shows results modified yesterday.
- Past 7 days - shows results modified in the last 7 days.
- Past 30 days - shows results modified in the last 30 days.
- Past 6 months - shows files and folders modified in the last 6 months.
- Past year - shows files and folders modified in the last 12 months.
- More than one year - shows files and folders older than one year.
Filter by time period
This filter limits search results to files and folders that have date-time tags pointing to a certain time period.
Filter by GPS coordinates
This filter is planned.
Full-text search
With full-text indexing enabled on a location, TagSpaces extracts the readable text of your files during indexing and makes it searchable by any keyword it contains.
Since version 6.12, full-text search across plain-text formats (TXT, MD, HTML, CSV, source code, etc.) is part of the free Lite edition. Indexing the office and document formats listed in the supported types table (PDF, DOCX, ODT, XLSX, PPTX, EPUB, …) remains a PRO
capability.You can activate this feature for each location individually in the Edit Location dialog. Once activated, the next indexing pass will pull the text out of supported files and merge it into the index.
Supported file types
Categories marked with PRO
require TagSpaces Pro; the others are free since version 6.12.| Category | Extensions | Notes |
|---|---|---|
| Plain text | .txt, .md, .marp | Markdown and Marp presentations |
| HTML family | .htm, .html, .xhtml, .shtml, .mhtml | Body text extracted, scripts/styles stripped |
.eml | Headers and body treated as plain text | |
| Web shortcuts | .url, .website, .webloc, .desktop | URL, name, and description fields |
| Tabular | .csv | Cell values, commas and semicolons treated as separators |
| Contacts | .vcf (vCard) | Name, email, organisation, title, phones, etc. |
| Documents PRO | .docx, .pdf | Word documents and searchable PDFs (OCR must be done before) |
| Spreadsheets PRO | .xlsx, .ods | Shared strings and inline cell values |
| Presentations PRO | .pptx, .odp | Slide text, speaker notes, slide layouts |
| OpenDocument text PRO | .odt | Body, styles, metadata |
| Ebooks PRO | .epub | All XHTML chapter files inside the archive |
Embedded images and attachments
Screenshots embedded as data:image/... URLs in Markdown or HTML, inline base64 icons in .url / .webloc files, and PHOTO fields in vCards are stripped out before the text is indexed. This keeps tsft.jsonl (the fulltext index file) small, keeps indexing fast, and keeps searches relevant.
Binary attachments inside MHTML, EPUB, or Office archives are ignored for the same reason — only the readable content goes into the index.
Chinese, Japanese, Korean
CJK text has no spaces between words, so TagSpaces indexes it as overlapping character bigrams in addition to individual characters. The query 中国 will find documents containing 中国, 美国中国人, and similar runs. Single-character CJK queries (e.g., 中) are also supported — the outer Latin one-character-query gate doesn't apply to CJK.
The split index format
Since version 6.11, the fulltext content is stored in a separate tsft.jsonl file alongside the main tsi.json metadata index. Consequences for users:
- Searches that don't need fulltext (tag filters, filenames, etc.) load only
tsi.json— much faster. - Fulltext is loaded on demand the first time you run a text search in a given session.
- The regular index stays small even when fulltext indexing is enabled on huge locations.
Older indexes are read transparently: a location last indexed with the previous monolithic format will be upgraded to the split format the next time the index is rebuilt.
Activating full-text search on locations with many large files increases initial indexing time and disk usage for the index. Incremental indexing mitigates this on subsequent runs — only new or modified files are re-processed.
Indexing
TagSpaces has an integrated file and folder search based on an index. The index is created the first time you run a search on a location and refreshed automatically when it becomes older than the location's configured maximum age (10 minutes by default). This maximum age can be adjusted individually in the properties of each location — locations that rarely change can safely use an age of a week or a month.
Incremental indexing
Starting with version 6.11, re-indexing is incremental by default. On the second and any subsequent run, TagSpaces first performs a lightweight walk of the directory tree that only reads file timestamps and sizes, then:
- Unchanged files are kept from the existing index as-is (including their extracted text).
- New files are indexed from scratch.
- Modified files (different mtime or size) are re-extracted.
- Deleted files are removed from the index.
Re-indexing a 50,000-file location typically takes a few seconds instead of minutes when most files haven't changed. You can force a full re-index any time from the search menu ("Update all location indexes") or with the --force flag on the command-line tool.
Large locations and manual updates
If your location contains a very large number of files (>50,000), it is recommended to split it into two or more locations or to disable automatic indexing.
When automatic indexing is disabled, the index can be refreshed in the following ways:
- In the menu of each location in the location manager, there is an item called Refresh Location Index.
- All indexes can be updated at once from the search menu with the option Update all location indexes.
- Create or refresh the index manually with the command-line tools.
Limit the search results
By default, TagSpaces limits the number of search results to 1,000 files and folders. This limitation also applies to the maximum number of files that can be displayed in a single folder. In the general tab of the settings, there is a field where you can increase or decrease this limit. See the next screenshot.
Global search
TagSpaces Pro offers searching across all locations, called Global search. It works on both local and remote S3-based locations. You can activate this feature by clicking the Global button in the search area, as shown in the following screenshot.
Once in Global search mode, you will see an additional option called Force re-indexing all locations. Activating this checkbox will force TagSpaces to create a new index for each location before searching in it. This option delivers the most accurate search results but may take more time, especially when re-indexing remote locations or locations with many files. Incremental indexing still applies — only new or changed files are re-processed unless you also pass --force.
All other search settings work the same as in single-location searches. The search result limit applies here; once the limit is reached, TagSpaces will stop the search and not continue searching the remaining locations.
If you are in the context of a given workspace, the global search will deliver only results from the locations assigned to the current workspace.
Search history
This feature can be activated in the app's advanced settings, where you can choose how large the search history should be. Once activated, the app will save the last searches performed, including the search query and the location where they were executed.
The search history can also be disabled by choosing disabled from the dropdown or deleted by clicking the trash bin icon.
Stored search queries
This feature allows you to store commonly used search queries for later use. The following video demonstrates how to use this feature.
Stored searches are location-independent, meaning they can be executed on any location.
Create stored searches
Edit stored searches
Export and import
PROThis functionality allows you to share commonly used search queries with others who are working with you on the same file base.
In the three-dot menu of the stored search area, you will find menu entries for exporting and importing search queries. The file format for the export is JSON, which can be opened and edited with any modern text editor. If needed, you can fine-tune the search queries in the editor and distribute them to other TagSpaces installations for yourself or colleagues.
Due to the unique IDs associated with search queries, TagSpaces can recognize if the query has already been imported, allowing you to skip the re-import or import the newer version. An example export can be found in the documentation.
